# 3. 引导扇区编程(16位实模式)
即使提供了事例代码,相信你也会发现在二进制编辑器上使用机器码令人沮丧,你必须记录这些机器码,否则需要不断的查阅文档来找到让CPU完成特定的功能机器码。幸运的是你并不孤单,因此汇编程序出现了,它可以将更人性化的指令翻译成特定CPU上的机器代码。
在本章中,我们将探索越来越复杂的引导扇区编程,来熟悉我们的程序运行之上的汇编环境和引入操作系统之前的贫瘠环境。
# 3.1 回顾引导扇区
现在,我们要使用汇编语言来重写第二章中使用二进制编写的引导扇区,这样即使是用很底层的汇编语言,我们也可以体验到使用高级语言的价值。
我们可以将这些代码汇编成机器代码(我们的CPU可以解释的字节序列, 称为指令):
$nasm boot_sect.asm -f bin -o boot_sect.bin
boot_sect.asm 中保存的是图表3.1的源代码,boot_sect.bin 是汇编后的机器代码,我们可以用来作为磁盘上的引导扇区。
注意我们使用-f bin 选项来告诉nasm生成原始机器代码,而不是生成含有附加元信息的代码包,在通常操作系统环境下,这些元信息用来帮助连接其他的库。我们不需要这些元信息,现在除了底层的BIOS服务程序。这是这个计算机上运行的唯一软件,尽管这这个阶段除了无限的循环我们没有提供任何功能,但是很快我们将基于此来构建我们的完整系统。
; Define a label, "loop", that will allow
; us to jump back to it, forever.
; Use a simple CPU instruction that jumps
; to a new memory address to continue execution.
; In our case, jump to the address of the current
; instruction.
loop:
jmp loop
; When compiled, our program must fit into 512 bytes,
; with the last two bytes being the magic number,
; so here, tell our assembly compiler to pad out our
; program with enough zero bytes (db 0) to bring us to the
; 510th byte.
times 510-($-$$) db 0
; Last two bytes (one word) form the magic number,
; so BIOS knows we are a boot sector.
dw 0xaa55
图表 3.1: 一个使用汇编语言编写的简单的引导扇区
比起将其保存到软盘的引导扇区并重新启动机器,我们可以通过运行Bochs来方便地测试此程序:
$bochs
或者,根据我们的偏好和模拟器的可用性,我们可以使用QEmu,如下所示:
$qemu boot_sect.bin
或者,您可以将这个镜像文件加载到虚拟化软件中,或者将其写入某个可引导介质中,然后从真实的计算机引导它。请注意,当您将镜像文件写入某个可引导介质时,并不意味着您要将该文件添加到该介质的文件系统中:您必须使用适当的工具在底层意义上直接写入代码到介质(例如,直接写入磁盘的扇区)。
如果我们想更容易的看到汇编器到底创建了什么字节,我们可以运行下面的命令,这个命令使用容易读的十六进制格式展示文件内二进制内容。
od -t x1 -A n boot sect.bin
这个命令的输出应该看起来很熟悉。
恭喜,你刚用汇编语言编写了一个引导扇区。正如我们将看到的,所有的操作系统都是这样启动的,然后将自己提升到更高级的抽象(例如高级语言,如C/C++)
# 3.2 16位实模式
CPU制造商必须不遗余力地保持他们的CPU(即他们的特定指令集)与早期的CPU兼容,这样旧的软件,特别是旧的操作系统,仍然可以在现代的CPU上运行。
英特尔为了兼容CPU采用的解决方案是模拟该家族中最古老的CPU:英特尔8086,它支持16位指令并且没有内存保护的概念,内存保护对于现代操作系统的稳定性至关重要,因 它允许操作系统限制用户进程访问内核内存,无论用户进程有意或无意的访问内核内存,都可能导致用户进程避开安全机制或者直接导致整个系统瘫痪。
因此,为了向后兼容,CPU在启动初始化时以16位实模式启动是很重要的,这要求现代操作系统显式地切换到更高级的32位(或64位)保护模式,但允许旧的操作系统无意识的继续运行在现代操作系统上,稍后我们将详细介绍从16位实模式到32位保护模式的重要步骤。
通常我们说一个CPU是16位的,意思是它一次最多能处理16位的指令。例如:一个16位的CPU将有一个特殊的指令,这个指令能够在一次CPU周期内将两个16位的数字相加,如果某个流程需要将32位的数据相加,那么这将花费更多的使用16位加法的周期。
首先我们将探索16位实模式的环境,因为所有的操作系统都是从这开始的,然后我们将学习怎么切换到32位保护模式及这样做的主要好处。
# 3.3 嗯, Hello ?
现在我们将写一个看起来简单的引导程序-打印一条短的信息到显示器上。为了实现这个引导程序,我们需要学习一些基础知识,CPU是怎么工作的我们怎么使用BIOS来帮助我们操纵显示器设备。
首先,让我们想想我们要做什么。我们希望在显示器上打印一个字符但是我们不知道怎么与显示设备交流,因为可能有很多类型的显示设备并且它们可能有不同的接口。这就是为什么我们需要使用BIOS,因为BIOS已经自动检测了硬件,从BIOS能在启动时打印关于自检的信息到显示器就可以看出来,所以可以方便的提供这方面的服务给我们。
然后下一步,我们希望告诉BIOS 打印一个字符给我们。但是我们怎么告诉BIOS打印字符呢?这里没有Java库来调用输出到显示器上-这是梦想而已,但我们可以确认的是在计算机内存的某个地方有一些BIOS机器代码知道怎么打印输出到显示器。我们可能可以在内存中找到BIOS代码然后执行它,但是事实是,这样做很麻烦而且不值得,并且当在不同的机器上不同的BIOS内部程序有差异时,这样做容易产生错误。
这里我们可以使用计算机内部的基础机制:interrupts(中断)
# 3.3.1 中断(Interrupts)
中断是一种机制,它能允许CPU暂定正在做的任务转而执行其他的高优先级任务,然后返回继续源任务。中断可以被软件指令(例如:0x10)或者一些需要高优先级操作(如:从网络上读取数据)的硬件触发。
每一个中断都由一个唯一的数字表示,这个数字是中断向量的索引,BIOS在内存开始处(在物理地址0x0处)初始化一个向量表,表内包含指向中断服务程序(ISRs)的指针。一个 ISR 就是一段处理特定中断(如:可能是从磁盘驱动或者网卡读取新的数据)的机器指令的序列,很像我们的引导扇区代码。
所以,BIOS向中断向量添加了自己针对计算机某些特定方面的ISRs。例如:0x10中断导致显示相关的ISR被调用,,0x13中断是关于磁盘I/O 的ISR。 然而,如果给每个BIOS程序分配一个中断是很浪费的,所以BIOS通过我们可以想到的一个大的switch语句来复用ISRs,通常基于CPU上的通用寄存器ax的值来触发具体的中断。
# 3.3.2 CPU 寄存器(Registers)
就像在高级语言中使用变量一样,在特定的程序中将数据临时储存起来很有用。所有的x86CPU都有4个通用寄存器,ax bx,cx,和dx 用来达到临时储存的目的。每个通用寄存器可以保存1个字(2个字节,16位)的数据,并且可以以相对于访问主存来说无延迟的速度读写。在汇编程序中,一个最常见的操作就是在寄存器之间移动(确切的说是复制)数据:
mov ax, 1234 ; store the decimal number 1234 in ax
mov cx, 0x234 ; store the hex number 0x234 in cx
mov dx, ’t’ ; store the ASCII code for letter ’t’ in dx
mov bx, ax ; copy the value of ax into bx, so now bx == 1234
注意 mov 操作的目的是第一个参数而不是第二个,不过在不同的汇编语言中这种对于目的参数的位置的约定不同。
有时仅操作一个字节很方便,所以寄存器允许单独的设置高位字节和低位字节:
mov ax, 0 ; ax -> 0x0000, or in binary 0000000000000000
mov ah, 0x56 ; ax -> 0x5600
mov al, 0x23 ; ax -> 0x5623
mov ah, 0x16 ; ax -> 0x1623
# 3.3.3 汇总
回到之前的需求,我们希望BIOS能为我们打印一个字符到显示器,我们可以通过设置ax寄存器的值为某些BIOS定义好的值,然后触发特定的中断来调用特定的BIOS程序,我们需要的这个特定的服务程序就是BIOS滚动打印服务程序,这个BIOS程序可以向显示器打印单个字符并将光标向前移动一位,为下一次打印做准备。这里列出了完整的BIOS程序,向您显示了要使用的中断以及如何在中断之前设置寄存器。 在这里,我们需要中断0x10,并将ah设置为0x0e(以指示打印模式),然后将al设置为我们希望打印的字符的ASCII码。
;
; A simple boot sector that prints a message to the screen using a BIOS routine.
;
mov ah, 0x0e ; int 10/ah = 0eh -> scrolling teletype BIOS routine
mov al, ’H’
int 0x10
mov al, ’e’
int 0x10
mov al, ’l’
int 0x10
mov al, ’l’
int 0x10
mov al, ’o’
int 0x10
jmp $ ; Jump to the current address (i.e. forever).
;
; Padding and magic BIOS number.
;
times 510-($-$$) db 0 ; Pad the boot sector out with zeros
dw 0xaa55 ; Last two bytes form the magic number,
; so BIOS knows we are a boot sector.
图表3.2 展示来整个引导扇区程序,注意再这个例子中我们只需要设置一次ah,然后修改al 为不通的字符就行来。
b4 0e b0 48 cd 10 b0 65 cd 10 b0 6c cd 10 b0 6c cd 10 b0 6f cd 10 e9 fd ff 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
*
00 00 00 00 00 00 00 00 00 00 00 00 00 00 55 aa
图表3.3
为了完整性, 图表3.3 显示了这个引导扇区的原始机器代码。这是精确的告诉CPU做什么的实际字节。如果您对编写这样一个几乎毫无用处的程序所涉及的大量工作和理解感到惊讶,那么请记住,这些指令非常紧密地映射到CPU的电路,因此它们一定很简单 ,但速度也很快。 您现在已经真正了解了您的计算机。
# 3.4 Hello World!
现在我们将尝试一个比hello程序稍微高级一点的版本。这个版本将引入更多的CPU基础知识并了解我们的引导扇区被BIOS装载到的内存环境。
# 3.4.1 内存,地址,和标签 (Memory, Addresses, Labels)
我们之前介绍过CPU怎么从内存中取指执行,以及BIOS怎么加载我们的512字节的引导扇区到内存中并完成初始化,然后告诉CPU跳转到我们代码的开始处,并从这里开始执行一条指令,然后下一条,下一条,等等。
所以我们的引导扇区存在于内存中的某个地方,但是在哪里呢?我们可以把主存想象成能通过地址独立访问的长字节序列,所以如果想知道第54个字节的内容,54就是我们的它的地址,通常使用16进制的格式将地址表示为0x36更方便。
所以引导扇区最开始处即第一个机器代码字节在内存的某个地方,并且是BIOS将它们置于这个地方的。直到我们了解事实之前,我们可以先假设BIOS将我们的代码加载到内存的最开始处,即在地址0x0处。不过,这显然没有这么简单,因为我们知道在BIOS在加载我们的代码之前BIOS自己已经完成了初始化工作,并持续提供例如时钟中断和磁盘驱动等服务,所以BIOS服务(例如 ISRs, 打印输出到显示器服务,等等)自己本身也要存放到内存的某处,并且在使用这些服务期间,维持在内存中(不被别的代码覆盖)。还有,我们之前已经知道了,中断向量表存放在内存的开始处,如果BIOS 将我们的代码加载到这里,我们的代码将覆盖中断向量表,,因为中断序号于 ISR 之间的映射关系已经规定好了,当下一个中断出现时,计算机将会执行错误的中断服务,并导致崩溃并重启。
经过证明,BIOS 通常将引导扇区加载到0x7c00地址处,使用这个起始地址将保证代码不会覆盖其他重要的服务。图表3.4展示了当引导扇区刚被加载时计算机内典型的内存分布。所以,我们可能会命令CPU向内存中的任何地址写数据,这会导致发生严重的问题。因为内存中已经存放了一些其他的重要的服务例如时间中断和磁盘驱动。
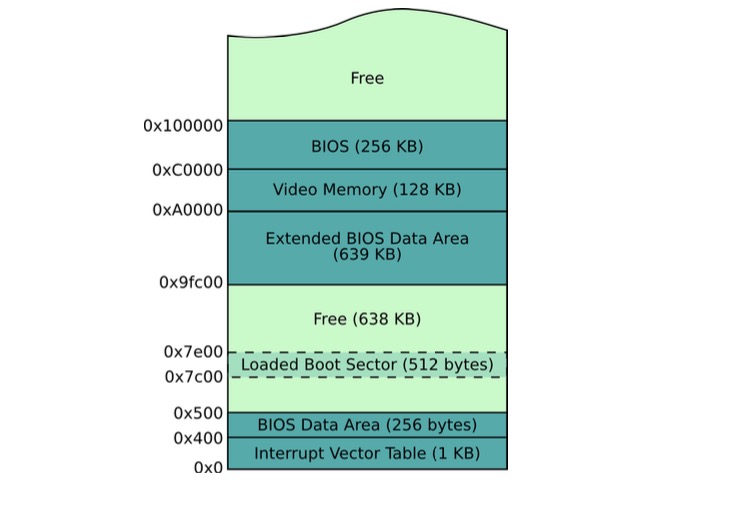
图表3.4: 典型的启动后内存分布
# 3.4.2 'X' 标记位置
现在我们将玩一个"找字节"的游戏,这个游戏将介绍内存引用,汇编语言中标签的使用,以及知道BIOS将我们的代码加载到哪里的重要性。我们将编写一个汇编程序,实现保存一个字符的字节数据,然后将这个字符打印到显示器上。为了完成这个程序,我们需要计算出它的绝对内存地址,然后我们就可以它加载到al寄存器中最后让BIOS打印输出它,如下练习:
;
; A simple boot sector program that demonstrates addressing.
;
mov ah, 0x0e ; int 10/ah = 0eh -> scrolling teletype BIOS routine
; First attempt
mov al, the_secret
int 0x10 ; Does this print an X?
; Second attempt
mov al, [the_secret]
int 0x10 ; Does this print an X?
; Third attempt
mov bx, the_secret
add bx, 0x7c00
mov al, [bx]
int 0x10 ; Does this print an X?
; Fourth attempt
mov al, [0x7c1e]
int 0x10 ; Does this print an X?
jmp $ ; Jump forever.
the_secret:
db "X"
; Padding and magic BIOS number.
times 510-($-$$) db 0
dw 0xaa55
首先,当我们在程序中声明一些数据时,我们在它前面加上一个标签(the_secret).我们可以将标签放置到程序的任何位置,使用它们的唯一目的是为我们提供从代码开始到特定指令或数据的方便的偏移量。
b4 0e b0 1e cd 10 a0 1e 00 cd 10 bb 1e 00 81 c3 00 7c 8a 07 cd 10 a0 1e 7c cd 10 e9 fd ff 58 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
*
00 00 00 00 00 00 00 00 00 00 00 00 00 00 55 aa
图表3.5:
如果我们直接看图表3.5中的汇编后的机器代码,我们可以找到我们的'X'字符, 它的16进制ASCII码为0x58,它相较于代码的起始位置的偏移量为30(0x1e), 直接位于我们开始在引导扇区填充0的位置之前;
如果我们运行这个程序,我们会看到只有后两次尝试打印成功。
第一次尝试失败的问题是它试图将直接偏移量加载到al作为字符来打印。但是实际上我们需要打印的是在这个偏移量位置的字符,而不是偏移量本身。如后面一条尝试的例子,通过在偏移量外面加上方括号,可以命令CPU做正确的事情-保存一个地址中的内容。
那为什么第二个尝试失败了呢?它的问题是CPU将偏移量当作以从内存开始处的偏移。而不是从我们的代码加载的地方开始的偏移。这将导致这个偏移量指向到中断向量表上。在第三个尝试中,我们使用CPU add指令给 the_secret 偏移量加上了0x7c00地址,我们相信BIOS将我们的代码加载到0x7c00地址处。我们可以把 add 指令看作高级语言表达式 bx = bx + 0x7c00。我们现在计算出了'X'在内存中正确的地址,接着可以使用指令 mov al, [bx]将这个地址的内容存放到al寄存器中,为BIOS打印函数做准备
在第四个尝试中,我们试着跟聪明一些,在引导扇区被BIOS装载入内存后提前计算‘X’ 的地址。我通过提前检查二进制代码找到了地址0x7c12(查看 图表3.5),在图表中显示,‘X’相对于我们的启动扇区的开始位置偏移0x1e(30)个字节。最后一个尝试提醒了我们为什么标签如此有用。因为如果没有标签我们将从编译后的代码中计算偏移量。如果代码的变更改变了偏移量改变,我们还需要更新偏移量。
这里我们看到了BIOS确实将我们的引导扇区加载到了0x7c00地址处。并且我们也看到了汇编代码中的标签与寻址的关系。
在代码中频繁的计算这种标签与内存的偏移很不方便。所以很多汇编程序在汇编期间纠正标签引用,如果你在你的代码的开始处包含以下指令明确告诉汇编程序你期望的代码在内存中的地址:
[org 0x7c00]
# 问题1
当这个 org 指令添加到了这个引导扇区程序上,你觉得程序将会有怎样的打印结果? 为了获得好成绩,请解释为什么会这样。
# 3.4.3 定义字符串
假设您想在某个时候打印一条预定义的消息(例如“引导操作系统”)到屏幕上;你会在汇编程序中如何定义这个字符串?我们得提醒自己计算机对字符串一无所知,字符串只是存储在内存某处的数据单元系列(例如字节、单词等)。
在汇编中我们可以像下面这样定义字符串:
my_string:
db ’Booting OS’
我们已经见过了 db 指令,可以翻译为“declare byte(s) of data”,这个指令告诉汇编程序将后面的字节直接写入到二进制输出文件中(即不要将他们翻译为处理器指令)。因为我们使用引号包裹数据,这样汇编程序就知道将其中的每个字符转换成ASCII字节码。注意,我们通常使用标签(例如:my_string)来标记数据的开始,否则我们没有其他容易的方法用来在我们的代码中引用数据。
在这个例子中,我们忽略了一件事:知道一个字符串有多长和知道它在哪里一样重要。毕竟所有处理字符串的代码是由我们编写的,所以有一个一致的策略来了解字符串的长度是很重要的。有几种可能,但惯例是将字符串声明为以null结尾,这意味着我们总是将字符串的最后一个字节声明为0,如下所示:
my_string:
db ’Booting OS’,0
当需要遍历一个字符串时,可能是轮流打印它的每一个字符,我们可以容易的知道什么时候遍历结束了。
# 2.4.4 使用栈
当提及底层计算的话题,我们经常听到大家谈论栈就像它是一种特殊的东西。栈其实是这些的问题的简单解决方案而已:CPU提供临时存储我们的程序的局部变量的寄存器的数量是有限的,但是我们通常需要比寄存器更多的临时储存。这时,显然我们可以使用主存,但是当读取或者写入时指明具体的内存地址很不方便,特别是当我们无需关心数据到底存放到哪里,只要我们能够容易的获取数据就够了。并且,我们将在后面看到,栈对于传递参数以实现函数调用也很有用。
所以,CPU提供了 push 和 pop 2条指令,分别用于重栈顶储存值和取出值,这样就不需要关心他们到底存放到哪里。注意,然而我们不能push 或者 pop 单个字节到栈上:在16位模式下,栈只能在16位长度下工作。
栈是通过 bp 和 sp 这两个特殊的CPU 寄存器实现的,它们分别维护栈基(即栈底)和栈顶的地址。随着我们不断的将数据压栈,栈将越来也大。 所以为了当栈生长的很大时没有覆盖重要程序(例如BIOS代码或我们的代码)的危险,我们通常将栈基设置在离这些重要程序很远的地方。堆栈的一个令人困惑的地方是它实际上是从基指针向下增长的,所以当我们发出一个push时,值实际上存储在bp地址的下面,而不是上面,而sp则按值的大小递减。
下面 图表3.6中的引导扇区程序展示了栈的使用。
;
; A simple boot sector program that demonstrates the stack.
;
mov ah, 0x0e ; int 10/ah = 0eh -> scrolling teletype BIOS routine
mov bp, 0x8000 ; Set the base of the stack a little above where BIOS
mov sp, bp ; loads our boot sector - so it won’t overwrite us
push ’A’ ; Push some characters on the stack for later
push ’B’ ; retreival. Note, these are pushed on as
push ’C’ ; 16-bit values, so the most significant byte
; will be added by our assembler as 0x00.
pop bx ; Note, we can only pop 16-bits, so pop to bx
mov al, bl ; then copy bl (i.e. 8-bit char) to al
int 0x10 ; print(al)
pop bx ; Pop the next value
mov al, bl
int 0x10 ; print(al)
mov al, [0x7ffe] ; To prove our stack grows downwards from bp,
; fetch the char at 0x8000 - 0x2 (i.e. 16-bits)
int 0x10 ; print(al)
jmp $ ; Jump forever.
; Padding and magic BIOS number.
times 510-($-$$) db 0
dw 0xaa55
图表3.6: 使用
push与pop操作栈
# 问题2
图表3.6中的代码将以什么顺序打印什么? 字符‘C’的ASCII码存放在内存中的绝对地址是什么?为了验证你的想法,你会发现尝试修改代码将有帮助。但是需要确认为什么在这个地址。
译者给出的测试代码
;
; A simple boot sector program that demonstrates the stack.
;
mov ah, 0x0e ; int 10/ah = 0eh -> scrolling teletype BIOS routine
mov bp, 0x8000 ; Set the base of the stack a little above where BIOS
mov sp, bp ; loads our boot sector - so it won’t overwrite us
push ’A’ ; Push some characters on the stack for later
push ’B’ ; retreival. Note, these are pushed on as
push ’C’ ; 16-bit values, so the most significant byte
; will be added by our assembler as 0x00.
mov bx, 0x8000 ; 将bx 设置为 bp 的值
sub bx, 0x2 ; 减去 16 位 即 A 的地址保存到bx
mov al, [bx] ; 将bx存的地址的内容放到al中
int 0x10 ; 打印
sub bx, 0x2 ; 同上打印B
mov al, [bx]
int 0x10
sub bx, 0x2 ; 同上打印C
mov al, [bx]
int 0x10
pop bx ; Note, we can only pop 16-bits, so pop to bx
mov al, bl ; then copy bl (i.e. 8-bit char) to al
int 0x10 ; print(al)
pop bx ; Pop the next value
mov al, bl
int 0x10 ; print(al)
mov al, [0x7ffe] ; To prove our stack grows downwards from bp,
; fetch the char at 0x8000 - 0x2 (i.e. 16-bits)
int 0x10 ; print(al)
jmp $ ; Jump forever.
; Padding and magic BIOS number.
times 510-($-$$) db 0
dw 0xaa55
# 3.4.5 控制结构
当我们使用一门编程语言时,如果不清楚怎么编写一些它的基础控制结构(例如 if..then..elseif..else, for, 和 while.)我们将会不适应这门语言。这些结构运行代码执行可选的分支,是组成有用的程序的基础。
在编译后,这些高级控制结构简化为简单的跳转(jump)语句。实际上,我们已经见过最简单的循环事例了:
some_label:
jmp some_label ; jump to address of label
或者,另一种方式,具有相同效果:
jmp $ ; jump to address of current instruction
这个指令给我们提供了无条件跳转(即它一直跳转)的能力;但是我们通常需要基于某些条件跳转(例如一直循环知道我们循环了10次,等)。
在汇编语言中通过先执行一个比较指令,然后执行一个特定的条件跳转指令来实现条件跳转。
cmp ax, 4 ; compare the value in ax to 4 将ax 中的值与4 比较
je then_block ; jump to then_block if they were equal 如果结果相等则跳转到 then_block
mov bx , 45 ; otherwise , execute this code 否则执行这条代码
jmp the_end ; important: jump over the ’then’ block, 重要:跳过 then 代码块,
; so we don’t also execute that code. 这样我们就不会也执行 then 代码块中的内容
then_block:
mov bx , 23
the_end:
在类似C或者Java的语言里,上面的代码有这样的形式:
if(ax == 4) {
bx = 23;
} else {
bx = 45;
}
我们可以从汇编事例中看到,在幕后发生了一些事情,它将cmp指令与其执行的je指令相关联起来。这是一个事例关于CPU的特殊标记寄存器捕获cmp 指令的结果,然后接下来的条件跳转指令能够通过它来决定是否跳转到特定的地址。
基于之前的 cmp x, y 指令, 有以下的跳转指令可供使用:
je target ; jump if equal
jne target ; jump if not equal
jl target ; jump if less than
jle target ; jump if less than or equal
jg target ; jump if greater than
jge target ; jump if greater than or equal
# 问题3
从更高级的语言层面来规划条件代码,然后用汇编指令替换它总是很有用的。使用 cmp 及 合适的跳转指令将下面的伪汇编代码转换为完整的汇编代码。使用不同的 bx 来测试,并用你自己的语言来充分注释你的代码。
mov bx , 30
if (bx <= 4) {
mov al, ’A’
} else if (bx < 40) {
mov al, ’B’
} else {
mov al, ’C’
}
mov ah, 0x0e ; int=10/ah=0x0e -> BIOS tele-type output
int 0x10 ; print the character in al
jmp $
;Padding and magic number.
times 510-($-$$) db 0
dw 0xaa55
译者给出的答案
mov bx, 30
cmp bx, 4 ; 比较bx 与 4
jle mva ; 如果 bx <= 4 跳转到 mva 地址处
cmp bx, 40 ; 否则 比较 bx 与 40
jl mvb ; 如果bx 小与 40 跳转到 mvb 地址处
jmp mvc ; 否则 跳转到 mvc 地址处
mva:
mov al, 'A' ; 将 'A' 赋给 al
jmp end ; 跳转到 end 地址处
mvb:
mov al, 'B' ; 将 'A' 赋给 al
jmp end ; 跳转到 end 地址处
mvc:
mov al, 'C' ; 将 'A' 赋给 al
end:
mov ah, 0x0e ; 将0x0e赋给ah
int 0x10 ; 调用0x10号中断
jmp $
times 510-($-$$) db 0
dw 0xaa55
# 3.4.6 调用函数
在高级语言中,我们将较大的问题分解为函数,本质上函数就是我们程序中重复调用的通用程序(例如 打印消息,向文件写入,等),通常通过某种方式改变传递给函数的参数来改变输出的结果。在CPU层面,函数仅仅是向有用程序的地址的跳转然后在函数结束后跳回原来跳转指令紧接的下一条指令的地址。
我们可以这样模拟函数调用:
...
...
mov al, ’H’ ; Store ’H’ in al so our function will print it.
jmp my_print_function
return_to_here: ;This label is our life-line so we can get back.
...
...
my_print_function:
mov ah, 0x0e ;int=10/ah=0x0e -> BIOS tele-type output
int 0x10 ;print the character in al
jmp return_to_here ;return from the function call.
首先,注意我们怎么将 al 寄存器作为参数, 这里通过提前设置它然后供函数使用。
这就是使高级语言实现参数传递成为可能的方式,调用方和被调用方必须就将要传递参数的位置和数量达成一致。
遗憾的是,这种方法的主要缺陷是我们需要明确指出在调用函数后返回到哪里,所以我们不可能从我们程序的任何地方调用这个函数,因为它始终返回到相同的地址,这里就是 return_to_here 标签的地址。
借用参数传递的主意,调用者代码可以保存正确的返回地址(即 调用后紧接的地址)到一些大家都知道的位置,然后被调用的代码可以跳转到事先保存的地址。CPU在特殊寄存器ip(指令指针)中跟踪当前正在执行的指令,但是遗憾的是我们不能直接访问ip寄存器,但是CPU给我们提供了一堆指令,call 和 ret, 通过这两个指令我们能实现我们所希望的跳转和返回:call 指令的行为与 jmp 指令一样,不过它回在实际跳转之前将返回的地址push 到 栈;ret 指令能从栈 pop 下返回的地址然后跳转过去,如下:
...
...
mov al, ’H’ ; Store ’H’ in al so our function will print it.
call my_print_function
...
...
my_print_function:
mov ah, 0x0e ;int=10/ah=0x0e -> BIOS tele-type output
int 0x10 ;print the character in al
ret
我们的函数现在几乎是独立的了。但是这里还有一个问题,如果我们现在解决它,后面我们会庆幸自己的决定。这个问题是当我们在程序内调用一个函数,例如打印函数,在内部这个函数可能会修改若干寄存器来完成自己的工作(实际上,由于寄存器是稀缺的资源,所以它肯定会修改的),所以当我们的程序从函数返回后它可能并不能安全的继续工作,例如,保证我们存到dx 中的值仍然不变。
因此,对于一个函数立即将它将要修改的寄存器中的值推到栈上然后在返回之前将它们从栈上弹出(重置寄存器为原始值)是明智的,因为一个函数可能会使用很多通用寄存器。CPU 实现了2个方便的指令-pusha 和 popa ,这2个命令能方便的将所有的寄存器的值压栈或者出栈,例如:
...
...
some_function:
pusha ; Push all register values to the stack
mov bx, 10
add bx, 20
mov ah, 0x0e ; int=10/ah=0x0e -> BIOS tele-type output
int 0x10 ; print the character in al
popa ; Restore original register values
ret
# 3.4.7 包含文件
在辛苦的完成了看起来非常简单的汇编程序后,你可能想在多个程序中复用你的代码,nasm 允许你想下面这样直接包含外部文件:
%include "my_print_function.asm" ; this will simply get replaced by
; the contents of the file
...
mov al, ’H’ ; Store ’H’ in al so our function will print it.
call my_print_function
# 3.4.8 综合使用
我们现在已经有足够的对CPU和汇编的知识,来完成一个稍微复杂一点的“Hello Wrold”引导扇区程序。
# 问题4
将本节中的所有思想放在一起,制作一个独立的函数,用于打印以空结尾的字符串,其用法如下:
;
; A boot sector that prints a string using our function.
;
[org 0x7c00] ; Tell the assembler where this code will be loaded
mov bx, HELLO_MSG ; Use BX as a parameter to our function, so
call print_string ; we can specify the address of a string.
mov bx, GOODBYE_MSG
call print_string
jmp $ ; Hang
%include "print_string.asm"
; Data
HELLO_MSG:
db ’Hello, World!’, 0 ; <-- The zero on the end tells our routine
; when to stop printing characters.
GOODBYE_MSG:
db ’Goodbye!’, 0
; Padding and magic number.
times 510-($-$$) db 0
dw 0xaa55
为了获得好的分数,请确保函数在修改寄存器时非常小心,并且您对代码进行了充分的注释以展示你的理解。
# 3.4.8 总结
现在,我们仍会觉得没有向前走多远,对于我们现在正在工作的原始环境来说这没问题,很正常。如果我们将之前学习的都弄清楚了,我们就在前进的路上了。
# 3.5 护士, 把我的停诊器拿给我
目前为止,我们已经设法使计算机将我们加载到内存中的字符和字符串打印出来。但是很快我们将尝试从磁盘中加载一些数据,所以如果我们能将储存在内存上任何地址中的16进制值打印出来将很有帮助,这能帮助我们确认我们是否真的成功加载了任何东西。记住,我们没有奢侈美好的开发GUI(图新用户界面),它带有调试器,帮助我们小心的调试和检查代码。并且当我们遇到错误时不需要做任何事就是计算机就直接显示出来错误的给我们良好的反馈,所以我们需要自给自足。
我们已经编写了一个打印字符串的程序,这里我们将扩展这个程序来实现一个16进制打印程序 --- 一个在底层环境中需要被珍惜的程序。
让我们仔细的想想我们应该怎么做,从思考我们怎么使用这个程序开始。在高级语言中,我们会需要这样的服务:print_hex(0x1fb6), 这个服务将这个16进制数转化成 ‘0x1fb6’字符串 然后打印到显示器上。我们在3.4.6节中已经学过怎么在汇编语言中调用函数以及使用寄存器做为函数的参数,这里让我们使用 dx 寄存器作为参数用来保存我们希望 print_hex 函数打印的值:
mov dx, 0x1fb6 ; store the value to print in dx
call print_hex ; call the function
; prints the value of DX as hex.
print_hex:
...
...
ret
由于我们需要打印字符串到显示器,我们也可以复用之前的打印函数来完成这里的打印部分功能,然后我们主要的任务就是怎么使用我们的参数 dx 中的值来构造一个字符串就行了。当使用汇编工作时我们肯定不希望把事情弄复杂,所以我们使用下面的技巧来开始我们的函数。如果我们将完整的16进制字符串定义为程序中的一种模版变量,就像我们之前定义 “Hello, World” 消息一样,我们可以就可以使用字符串打印函数来打印它,然后我们的print_hex 程序的任务就是修改这个字符串模版来使用ASCII码反映16进制的值。
mov dx, 0x1fb6 ; store the value to print in dx
call print_hex ; call the function
; prints the value of DX as hex.
print_hex:
; TODO: manipulate chars at HEX_OUT to reflect DX
mov bx, HEX_OUT ; print the string pointed to
call print_string ; by BX
ret
; global variables
HEX_OUT: db ’0x0000’,0
# 3.5.1 问题5(高级)
完成 print_hex 函数的实现。你会发现 and 和 shr 这两个 CPU 指令很有用,你可以从互联网上找到这2个命令的使用信息。确保使用你自己的语言来注释并充分解释你的代码。
# 3.6 读取磁盘
我们已经介绍了BIOS,并且在计算机底层环境里编写了一些程序,但是在我们编写操作系统的路上还有一个小问题摆在我们面前:BIOS从磁盘的第一个扇区加载我们的引导代码,但是这是它加载的所有代码了,如果我们的的操作系统代码操作512字节怎么办呢?我猜一定会超过的。
操作系统通常不会只占用一个扇区(512字节),所以它们需要做的第一件事就是从磁盘中将其他剩下的代码加载到内存中,然后开始执行这些代码。幸运的是,BIOS给我们提供了程序允许我们操作驱动上的数据。
# 3.6.1 通过 Segments 来扩展内存访问
当CPU 运行在最初的16位实模式下,寄存器的大小最大为16位,这意味着指令能引用的最大的地址位0xffff,用今天的标准它只相当于区区64 KB(65536字节)。可能现在我们想要的简单操作系统不受这个限制的影响,但是对于一个现代的操作系统来说这个狭窄的盒子就太小了,所以了解这个问题的解决方案-分割很重要。
为了解决这个限制,CPU 的设计者们增加了一些特殊的寄存器 cs, ds, ss, 和 es 统称为段寄存器。我们可以将主存想象为被切割的很多片段,这些片段通过段寄存器索引,这样当我们指定一个16为的地址,CPU通过使用合适的段的起始地址加上我们指定的地址的偏移量来自动计算出绝对地址. 我的意思是储备明确的指定否则使用合适的段,CPU 会根据我们的指令的上下文选择合适的段寄存器来偏移我们的地址,例如:mov ax,[0x45ef] 指令中使用的地址将默认从 数据段(data segment) 偏移,使用ds索引;类似的还有 栈段(stack segment)ss 用来修改栈基指针 bp 的实际地址。
关于段寻址最让人困惑的是相邻的段对于16字节几乎完全重叠。所以不同的段和偏移量的组合能实际上指向同一个物理地址;现在说到这里就够了:我们在看一些例子之前很难真的掌握这些概念。
为了计算绝对地址 CPU 将段寄存器中的地址乘以16然后加上你的偏移地址;因为我们使用的是16进制,当我们需要乘以16时只需要简单的将值左移一位就行了(例如 0x42 * 16 = 0x420). 所以如果我们将ds 设置为 0x4d 然后执行 mov ax, [0x20], ax 中值的实际上将从地址0x4d0处加载
(16 * 0x4d + 0x20).
;
; A simple boot sector program that demonstrates segment offsetting
;
mov ah, 0x0e ;int 10/ah = 0eh -> scrolling teletype BIOS routine
mov al, [the_secret]
int 0x10 ; Does this print an X?
mov bx, 0x7c0 ; Can’t set ds directly , so set bx
mov ds, bx ; then copy bx to ds.
mov al, [the_secret]
int 0x10 ; Does this print an X?
mov al, [es:the_secret] ; Tell the CPU to use the es (not ds) segment.
int 0x10 ; Does this print an X?
mov bx, 0x7c0
mov es, bx
mov al [es:the_secret],
int 0x10 ; Does this print an X?
jmp $
the_secret:
db "X"
; Padding and magic BIOS number.
times 510-($-$$) db 0
dw 0xaa55
图表3.7展示了我们如何使用 ds 来实现类似第3.4.2节当时我们使用[org 0x7c00]来纠正标签寻址的问题。因为我们不实用 org 命令,当我们的代码被BIOS加载到地址0x7c00处,汇编程序就不会将标签偏移到正确的内存位置,所以第一次尝试打印一个'X'将会失败。但是如果我们将数据段寄存器为0x7c0后 CPU 将替我们执行这个偏移(0x7c0 * 16 + the_secret),所以第二次尝试会成功的打印'X'。在第三和第四次尝试中我们使用来相同的方式并得到相同的结果,但是这次我们明确的告诉CPU 在计算物理地址的时候使用通用寄存器es。
注意这里显示的CPU电路的局限性(至少在16位实模式下),像 mov ds, 0x1234 这样看起来正确的指令其实是错误的。仅因为我们能将一个地址字面量直接存到通用寄存器中(例如 mov ax, 0x1234 或者 mov cx, 0xdf),当这并不意味着我们能对任何类型的寄存器做这个操作,例如 段寄存器 等。像图表3.7中一样我们必须增加额外一步来通过通用寄存器来转化这个值。
所以 基于段的寻址允许我们触达更远的内存空间,上升到大概 1MB(0xffff * 16 + 0xffff).后面当我们切换到32为保护模式后,我们将看到怎么访问更多的地址,对于现阶段了解16位实模式下基于段的寻址就够了。
# 3.6.2 磁盘驱动工作原理
从机械上讲,硬盘驱动器包含一个或多个堆叠的盘片,它们在读/写磁头下旋转,很像旧的唱机,只是通过几张唱片一张叠在另一张上面增加了容量,,磁头来回移动以覆盖整个旋转盘片的表面;因为一个特殊的盘子在两面都是可读写的,所以一个读/写磁头可以浮在一个盘片上面,而在另一个盘片在下面。图3.8显示了一个典型的硬盘驱动器的内部情况,有一堆盘片和暴露在外面的磁头。请注意,软盘驱动也是这样的,软盘驱动通常只有一个双面软盘介质,而不是堆叠的盘片。
盘片的金属涂层使其表面的特定区域能够被磁头磁化或消磁,从而允许在盘片上有效的永久记录任何状态. 因此,能够准确地描述磁盘表面的某个状态被读取或写入的位置是非常重要的,因此 柱面-磁头-扇区(CHS)寻址方式被使用,这实际上是一个三维坐标系(见图表3.9)
柱面(Cylinder): 圆柱体描述了磁头与盘片外缘的距离,因为当几个盘片堆叠起来时,你可以看到所有的磁头相对堆叠的盘片选择了一个圆柱体,它也因此得名。
磁头(Head): 磁头描述了我们感兴趣的磁道(即柱面中那个具体的盘片表面)。
扇区(Sector): 环形的磁道被分割为很多扇区,通常每个扇区512字节,这些扇区可以使用扇区索引来引用。

图表3.8: 硬盘驱动内部
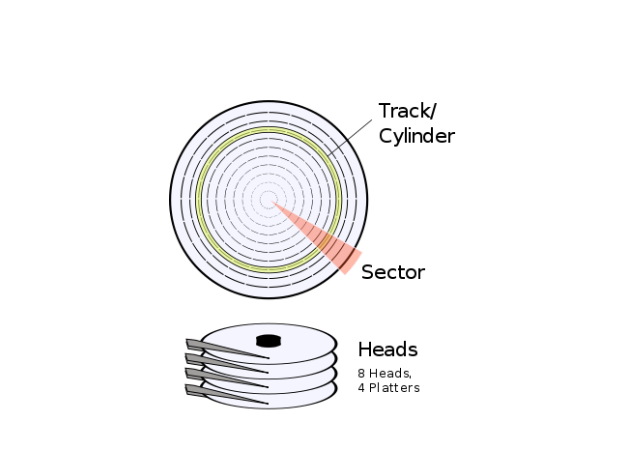
图表3.8: 硬盘的柱面、磁头、扇区结构
# 3.6.3 使用BIOS读取磁盘
很快我们将看到,特定的设备需要编写特定的程序来使用它,例如软盘需要我们在使用它之前显示的启动和停止读写磁头下面旋转磁盘的马达,然而大多数硬盘设备在本地芯片上有更多的自动功能。还有不同的设备使用的不同的总线技术连接到CPU 也会影响我们访问它们,幸运的是 BIOS 能提供一些磁盘程序它将通用磁盘设备的不同处抽象化来。
这里我们感兴趣的特殊 BIOS 程序通过在将al 设置为 0x02 后触发 0x13 中断来使用。这个BIOS 程序期望我们设置一些寄存器来描述使用哪一个磁盘设备,我们希望读取这个磁盘上的哪一块区域的代码块,以及将这些代码块保存到内存中何处。使用这个程序最困难的部分是,我们必须使用CHS寻址方案指定要读取的第一个块;接着,就是只需要填充预期寄存器,如下一个代码所描述。
mov ah, 0x02 ; BIOS read sector function
mov dl, 0 ; Read drive 0 (i.e. first floppy drive)
mov ch, 3 ; Select cylinder 3
mov dh, 1 ; Select the track on 2nd side of floppy
; disk, since this count has a base of 0
mov cl, 4 ; Select the 4th sector on the track -not,
; the 5th ince this has a base of 1.
mov al, 5 ; Read 5 sectors from the start point
; Lastly, set the address that we'd like BIOS to read the
; sectors to, which BIOS expects to find in ES:BX
; (i.e. segment ES with offset BX).
mov bx, 0xa000 ; Indirectly set Es to 0xa000
mov es, bx
mov bx, 0x1234 ; Set BX to 0x1234
; In our case, data will be read to 0xa000:0x1234, which the
; CPU will translate to physical address 0xa1234
int 0x13 ; Now issue the BIOS interrupt to do the actual read.
注意,由于某些原因(例如,我们索引了超出磁盘限制的扇区、试图读取故障扇区、软盘未插入驱动器等),BIOS可能在为我们读取磁盘时失败,因此了解如何检测这一点非常重要;否则,我们可能会认为已读取了一些数据,但实际上是目标地址上仍是我们发出读取命令之前的随机字节。幸运的是,BIOS更新了一些寄存器,以便我们知道发生了什么:特殊标志寄存器的进位标志(CF)被设置为发出一般故障的信号,al被设置为实际读取的扇区数,而不是请求的扇区数。发出BIOS磁盘读取中断后,我们可以执行以下简单检查:
...
...
int 0x13 ; Issue the BIOS interrupt to do the actual read.
jc disk_error ; jc is another jumping instruction, that jumps
; only if the carry flag was set.
; This jumps if what BIOS reported as the number of sectors
; actually read in AL is not equal to the number we expected.
cmp al, <no. sectors expected >
jne disk_error
disk_error :
mov bx, DISK_ERROR_MSG
call print_string
jmp $
; Global variables
DISK_ERROR_MSG: db "Disk read error!", 0
# 3.6.4 综合使用
如前所述,能够从磁盘读取更多数据对于引导我们的操作系统是至关重要的,因此在这里,我们将使用本节中的所学的知识编写一个有用的程序,这个程序只需从指定的磁盘设备上读取前n个扇区到引导扇区之后。
; load DH sectors to ES:BX from drive DL
disk_load:
push dx ; Store DX on stack so later we can recall
; how many sectors were request to be read,
; even if it is altered in the meantime
mov ah , 0x02 ; BIOS read sector function
mov al, dh ; Read DH sectors
mov ch, 0x00 ; Select cylinder 0
mov dh, 0x00 ; Select head 0
mov cl, 0x02 ; Start reading from second sector (i.e.
; after the boot sector)
int 0x13 ; BIOS interrupt
jc disk_error ; Jump if error (i.e. carry flag set)
pop dx ; Restore DX from the stack
cmp dh, al ; if AL (sectors read) != DH (sectors expected)
jne disk_error ; display error message
ret
disk_error:
mov bx, DISK_ERROR_MSG
call print_string
jmp $
;
DISK_ERROR_MSG db "Disk read error!", 0
为了测试这个程序,我们可以编写一个引导扇区程序,如下所示:
[org 0x7c00]
mov [BOOT_DRIVE], dl ; BIOS stores our boot drive in DL, so it's
; best to remember this for later.
mov bp, 0x8000 ; Here we set our stack safely out of the
mov sp, bp ; way, at 0x8000
mov bx, 0x9000 ; Load 2 sectors to 0x0000(ES):0x9000(BX)
mov dh, 2 ; from the boot disk. 译者注: 这里应该为2 因为这里只定义了3 * 512 字节,并没有6个字节的大小
mov dl, [BOOT_DRIVE]
call disk_load
mov dx, [0x9000] ; Print out the first loaded word, which
call print_hex ; we expect to be 0xdada, stored at address 0x9000
mov dx, [0x9000 + 512] ; Also, print hte first word from the
call print_hex ; 2nd loaded sector: shourld be 0xface
jmp $
%include "../print/print_string.asm" ; Re-use our print_string function
%include "../hex/print_hex.asm" ; Re-use our print_hex function
%include "disk_load.asm" ; Include our new disk_load function
; Global variables
BOOT_DRIVE: db 0
; Bootsector padding
times 510-($-$$) db 0
dw 0xaa55
; We know that BIOS will load only the first 512-byte sector from the disk,
; so if we purposely add a few more sectors to our code by repeating some
; familiar numbers, we can prove to ourselfs that we actually loaded those
; additional two sectors from the disk we booted from.
times 256 dw 0xdada
times 256 dw 0xface